Hi Ken
You can extend the text using a service like this
I’m piping the feeds through a Wordpress site I have in the hope I can strip all the images out and end up with plain text…
Hi Ken
You can extend the text using a service like this
I’m piping the feeds through a Wordpress site I have in the hope I can strip all the images out and end up with plain text…
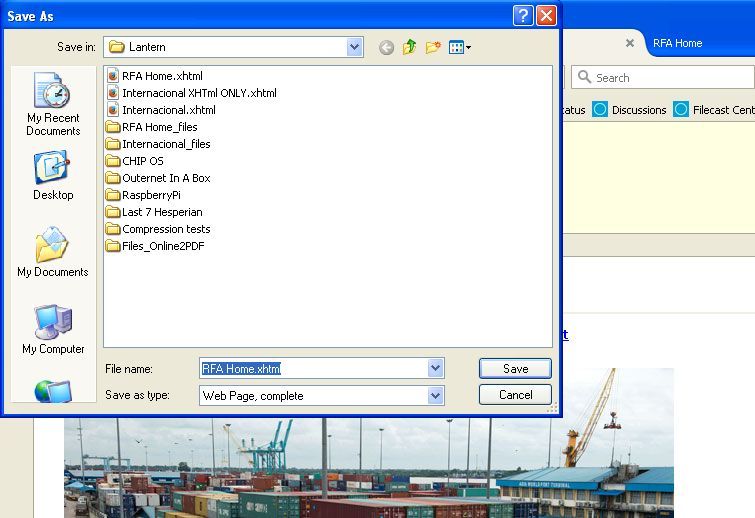
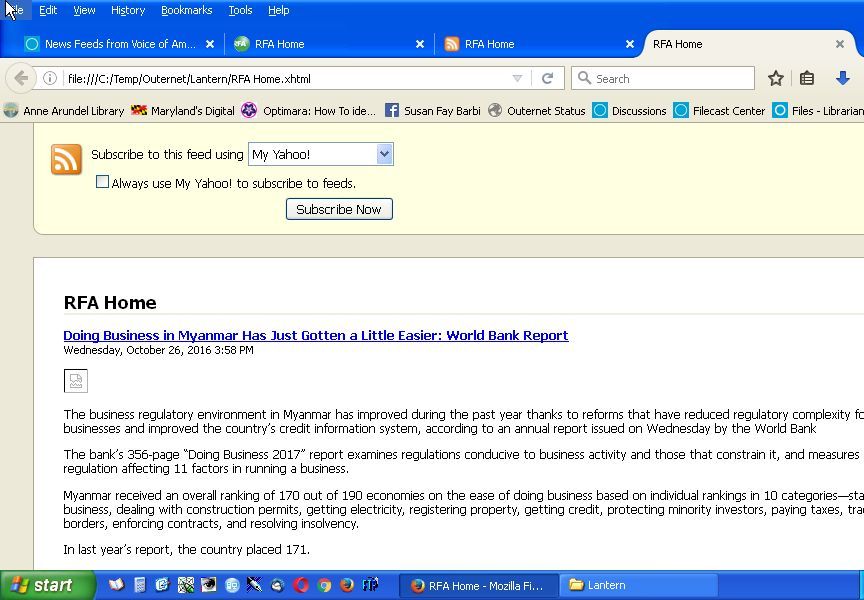
Hmm - - with Firefox I went to your RSS processing site that expanded the www.RTA.org RSS feed:
then saved it in Firefox as a Web Page, complete as shown here:
I used Firefox to open the .xhtml file that Firefox generated (which was a very small - 104 KB file with no pictures), and it opened like this (even when I went off line). However, I could not open the page with Chrome or Safari - must be some Firefox uniqueness to it. Here’s only the first page of 13:
Given its small size, wouldn’t this be the result we’d want Outernet to transmit? Ken
I selected 2 of Sam’s Creative Common RSS News feeds to create daily News PDFs for the next couple of days for Discussion Group member evaluation.
The first Americas - Voice of America provides VOA news content for the Americas, and the second Radio Free Asia provides Radio Fee Asia (RFA) news content.
Here are Sam’s creative commons newsfeed suggestions.
http://www.20minutos.es/rss/internacional/
https://theconversation.com/articles.atom?language=en
https://theconversation.com/articles.atom?language=fr
http://www.voanews.com/api/zq$omekvi_
http://www.voanews.com/api/z-$otevtiq
http://www.voanews.com/api/zo$o_egviy
http://www.voanews.com/api/zr$opeuvim
http://www.voanews.com/api/zj$oveytit
http://www.voanews.com/api/zoripegtim
http://www.rfa.org/english/RSS
http://www.rfa.org/mandarin/RSS
http://www.rfa.org/cantonese/RSS
http://www.rfa.org/burmese/RSS
I will input each of the 2 newsfeeds into http://fivefilters.org to create PDFs.
I will email these files (which for 28 Oct are135 kB and 240 Kb respectively after I used http://online2pdf.com to reduce their size) to Syed for uploading.
Yes the files are too large, but let’s start somewhere, and see what everybody thinks. Ken
Great Ken.
As you know, I think weather and NEWS will be the compelling app for Outernet L-Band success.
I had a dialog with @Syed and he asked me to post my work here.
Biggest issue I’m coming up against is file size creating PDFs. The PDFs look nice, but are large files

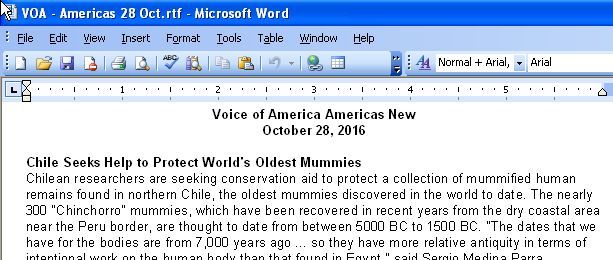
I took the raw output from the VOA - Amercas 28 Oct RSS feed and feed it into http://RSSdog.com to create text, and copied out the test into a simple text Word Processor. I make an RTF file which is 68 KB large, and a plain text file that is 41 KB.
Here’s a sample of the RTF file
And here’s a sample of the text file
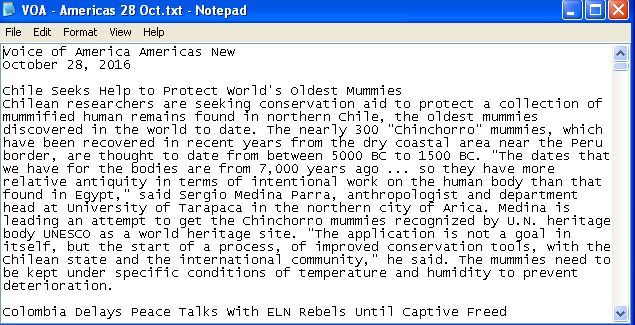
Creating these files requires a bit of hands on typing to make it read easily, so it’s not an automated process. I’ve uploaded both to Filecast today, so you be seeing them soon.
I’m going to do a few more days this way and upload both an .RTF and .TXT version of the VOA - Americas RSS feeds. Give me your ideas. Ken
Well that’s a bummer going from a 135 KB PDF to a 67 KB RTF to a 41 KB TXT - - @Syed changed the Filecast file size to 10 KB from 100 KB so I’m dead in the water. I’ll send these small files to him. Ken
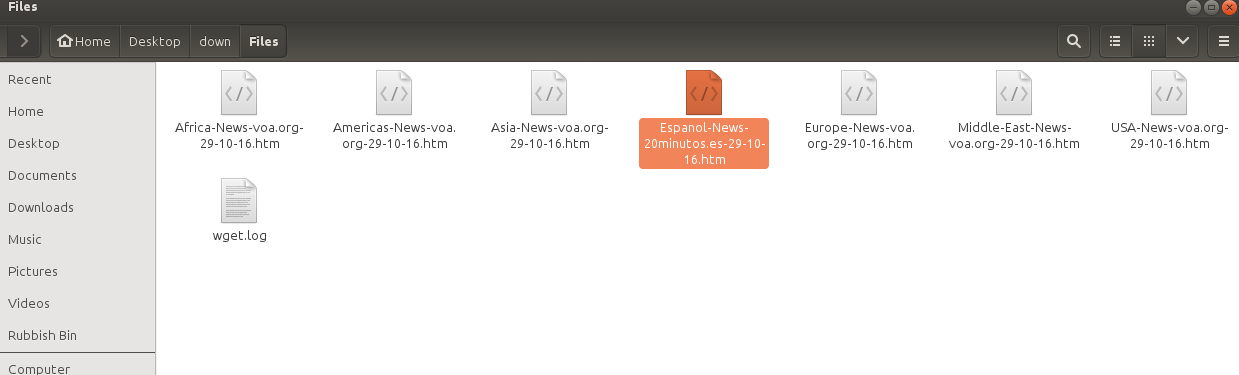
@syed @kenbarbi So here’s a dirty bash script:
(edit to above script to remove images, links, improve linespace, padding, font & add attribution)
Save the text in a file called ‘bash.sh’
It expects a folder called /Files, like this:
/some-folder-you-put.bash.sh
/Files
Then run the script with
$bash.sh
It will get the latest news in .htm file format and dump it in the files folder (I’m imagining this to be the folder that gets uploaded to filecast, and that you’d run it automatically every day from cron)
Hope it works out!
If you start using it I’ll tweak it some more (look into just downloading plain text and using a seperate CSS file to theme it & also Using Sed to properly strip out the IMG & Link text)
The reason for going down to 10kB is because we want to ensure that file are regularly being received, rather than waiting for an hour on just one. But this is still workable. Instead of a long digest for a file, we can break it up so that each article is a file.
Uh oh, Sam, you just went over my head 
I’m not Linux smart and am using Windows OS, so can’t try what you suggest.
Part of my dilemma is I don’t know what Outernet needs to automate news delivery. For sure they need the right sources, then they need an automated program that will periodically grab the news, package it, and send it to the satellites for ultimate view in their Librarian.
My desire is to move the News Delivery Initiative forward, and provide interim inputs for our user base until the system is fully automated. Ken
Hi Ken
All that script does is grab the .html files from RSS dog and save them as a datestamped file.
So it’s just like doing a right click > save as on the files in this post but an automated way of @syed grabbing the .html files without having to do it every day.
So if he puts it on their machine and sets it to run every 24 hours (using a thing called cron) then it will automate the news, albeit in a crude way…
I’m already working on a better way (lynx browser script & a seperate CSS file) but I hope Outernet will use it in the meantime…
Thanks
Sam
Sam, do you think it’s worthwhile for me to continue to grab News for Outernet, or should I concentrate on sources for Outernet to use in their automation? Ken
I guess it depends if @syed starts to use the script or not?
Finding sources is definitely worth doing. I’ve emailed a couple of places (with @syed 's consent) to ask for permissions.
I’ve recently heard back from the UN saying it’s OK to use
http://www.un.org/apps/news/rss/rss_top.asp
http://www.un.org/apps/newsFr/rss/
So that’s good… But i’d say finding content is probably the most useful thing?
I’m going to try to get the script running this week.
Finding content sources is definitely the most useful thing right now.
Great stuff.
Note i’ve tweaked it a bit today. This is the latest
It’s now fomatted a bit nicer & I’ve removed the links & images. It seems to work in most browsers
I was just looking at Slashdot.
Very concise. Many news readers around to see how they do it.
We almost need a Skype video conference to hash ideas over!
Excellent work Sam.
I look forward to reading the new sources of News.
@sam_uk I’m looking at the various News Feeds (specifically http://www.un.org/apps/news/rss/rss_top.asp) and am finding some do not render the entire article (only incliding the 1st paragraph) nor the date time of the article when processed by http://rssdog.com
Is there a setting I’m not changing in the conversion program? Ken
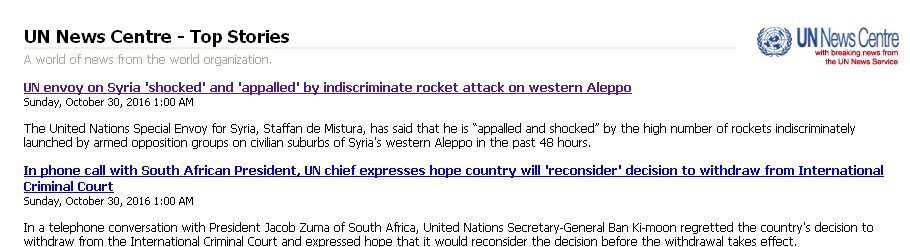
The UN Feed looks like this:
But in rssdog.com renders like this:
The content looks the same in both of those to me?
You can use a third party service like this to get the full feed.
Yes the contents are the same, but the question really has to do with extraction of all the text out of each article. That, I can’t seem to make happen. See - - here’s the blown up article, and there is more text below the first paragraph. Ken

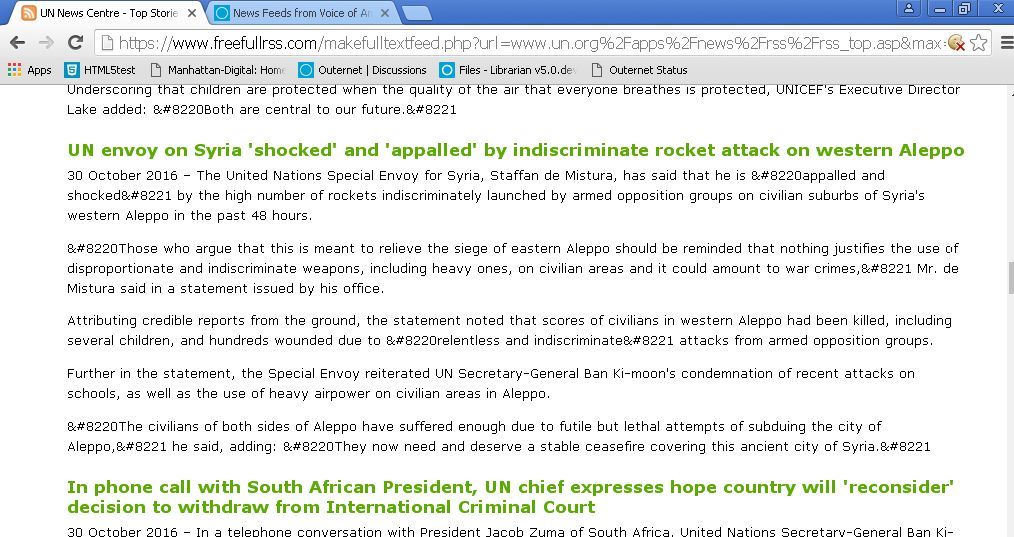
Ah - - now I see with http://freefullrss.com you get the whole story with a dateline - - good.
So then, that product can be processed further to create the feed Outernet needs and will get from your Linux script ![]()
Ken